《晚点聊》ep165,主播程曼祺访刚从港科大博士毕业的高深远——他从去年起在英伟达实习,正式加入英伟达具身智能实验室 GEAR;论文 DreamDojo 联合一作。109 分钟里他做了一件这个圈子里很少有人愿意做的事——亲口否定自己几年前在学界吃饭的那条路:「在学界继续做这个自动驾驶世界模型没有特别大的意思。」
大众视野里 AI 的故事现在是单线的——LLM、scaling law、参数竞赛、谁的 GPT 最强。这条线占了所有声量。但在 GEAR、DeepMind、字节 WAM、英国的 General Intuition 这些实验室内部,还有另一条线在跑——它不依赖往单一模型里更暴力地塞数据,而是让三个模型互相喂数据、互相打分、互相变强。这条线和 LLM 是两条独立的脊柱,都通向 AGI 但走法不同。
高深远这一期值得听的不是技术名词的扫盲——世界模型、策略模型、自进化循环、DreamDojo、DreamZero、JEPA、Genie、SIMA——他给了一组可证伪的判断:(1)这条脊柱今年会第一次"跑通";(2)Yann LeCun 那条 JEPA 隐空间路径很难直接接上现有基模;(3)Anthropic 不做 robotics 也不会 miss。这是一个 GEAR 内部研究员在镜头前给出的赌注。
以下是我们的拆解和判断。
一、"在学界继续做这个没有特别大的意思了"
听这一期,先听 01:05:28 这一段。高深远把自己从港科大博士做的几年自动驾驶世界模型研究——GAIA、Vista 都是他参与的——亲口判了一个"死刑":
"然后后来我发现在学界继续做这个自动驾驶世界模型没有特别大的意思。工业界的话,他们有很多这种高质量的视频,然后假如说我在学界继续做的话,就是我得从 YouTube 上去搞这些数据,它其实就是一个天然的劣势。"
这段话有两层信号。
第一层是数据壁垒已经成形。学界为了做世界模型要从 YouTube 抓视频,再自己写脚本去标 action label;车企手里有的是直接采的、有完整 action 标签的高质量驾驶视频。这是研究侧 vs 数据侧的非对称——一旦工业界进场,学界靠"巧思补数据"的窗口就关了。
第二层是研究范式的归并。高深远后面接着说:
"我感觉工业界喜欢做一些比较已经看到了成功迹象的一些路线,然后去把它用更大的规模去做出来。学校的话可能是做一些原创性的探索。但现在给我的感觉就是已经进入了有很多很成熟的技术路线可以选择,然后已经进入了规模化的阶段。"
这是一个重要的观察。当一个领域从"原创探索"进入"规模化复现"的临界点,学界的边际产出就会塌陷——AI 这一波在大模型上发生过一次(Transformer 之后,几乎所有突破都来自工业界),现在世界模型这一支也在重演。读到这里换一个问法:我们听到的"AI 是大模型公司之间的竞争"这个叙事,是不是漏掉了一整个赛道——它不是 OpenAI vs Anthropic vs Google 谁的 GPT 更强,是英伟达 vs DeepMind vs 字节 vs 一批新兴公司,在物理 AGI 这条线上重新排位。
二、世界模型不是一个东西,是四种东西
要听懂高深远后面的判断,必须先把"世界模型"这四个字拆开。这一期前 20 分钟是一个非常清晰的扫盲——按照"世界状态用什么表征"分,世界模型有四种:
- 隐空间表征(代表:Yann LeCun 的 JEPA)——把所有跟决策相关的东西压到一个抽象空间里
- 粒子/3D 表征(代表:李飞飞 World Labs / Marble)——显式 3D,主要服务游戏和自动驾驶
- 视频表征(代表:英伟达 Cosmos / DreamDojo / Google Genie)——直接用视频画面表示世界状态
- 多 agent 互联表征——做 V2X 那一脉,相对边缘
高深远本人押的是视频表征。他给的理由有三条值得划出来:
"我自己比较相信的就是纯预测 Video——就是用 Video 去做这个世界模型的表征空间。就是你 Video 进 Video 出,最终看到的也是 Video。它是端到端的,也是直接可以用这种互联网视频去作为 Data 训练。"
第一条:端到端——不需要中间标注,可以直接吃互联网视频。第二条:数据 rich——视频是地球上数据量最大的模态。第三条——也是他对 LeCun JEPA 路线的核心质疑:
"假如说你要构造一个新的表征空间,然后去做 world 的世界模型的话,他可能没有那么 make sense。他可能会有一些效率上的优势,但是他其实跟现在的这些语言和视频的基模型,就很难去直接的应用,直接接起来,直接去利用他们很强的泛化能力。"
这段批评比表面看起来狠。它说的根本就是"JEPA 接不上这个时代的基模"——一旦你切到一个 LLM 和视频模型都读不懂的隐空间,你就主动放弃了这十年 AI 行业积累的所有泛化能力。在一个基模迭代速度远超学术研究速度的时代,跟主流接得上比"理论上更优雅"重要得多。
所以这是一道生态站位的题,技术品位之外的题。
三、三体闭环:物理 AGI 的真发动机
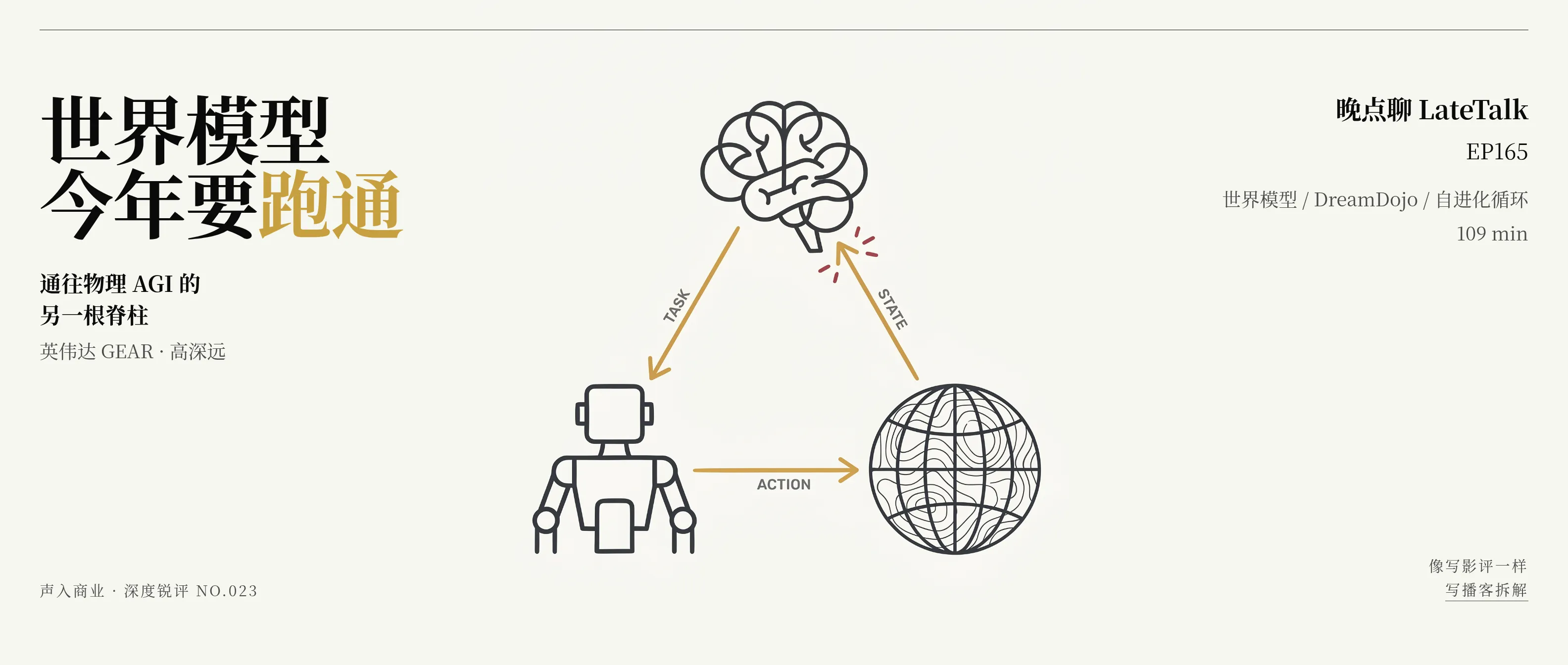
如果世界模型只是"能预测下一帧画面",它不会成为这一期的命题——这一期的命题是它和另外两个模型组成的闭环。
高深远把它讲得很直白:
"现在这个循环里有三个部分:通用的 Agent、Policy,然后世界模型,大家都在往这个泛化性的方面去推。所以说到未来某个点,我觉得可能就发生在今年,一旦它的误差累积到一个可接受的程度,整个循环会变得越来越简单,就相当于是可以实现自进化。"
这三者各干一件事——世界模型(DreamDojo / Genie / Cosmos)负责"你做了一个动作,我告诉你环境会变成什么样";策略模型(DreamZero / SIMA / VLA)负责"给定一个目标,我决定下一步怎么做";Agent 负责规划任务、评估世界模型预测得准不准,再把这个评估反过来给 Policy 做训练信号。
这三个东西在英伟达内部叫 DreamDojo + DreamZero + Agent,在 DeepMind 内部叫 Genie + SIMA + Agent。两家不同的公司在用同一个架构。
听到这里读者可能会问:这跟 LLM 那一套有啥本质区别?区别在训练信号的来源。LLM 的训练信号靠人类标注或人类反馈(RLHF),瓶颈在人;这个三体闭环的训练信号互相提供——Policy 在世界模型里试错、Agent 给 Policy 打分、Policy 变强后产生新数据再喂回世界模型。这是一个不依赖人类标注的递归飞轮。一旦三个组件的泛化能力都越过某个临界点,循环就开始自动加速。
高深远 36:24 那段话,是这一期分量很重的一句赌注:
"但是已经看到一些迹象,就是说大家都在往这个泛化性方面去推。所以说到未来某个点,我觉得可能就发生在今年,一旦这个东西连接起来之后,这个循环一旦比如说它的误差累积到一个可接受的程度,一旦达到那个点的话,你的 policy 就会开始提升,整个循环就会变得越来越简单。"
"今年"是一个具体到可以被证伪的时间点——2026 年。这是一个 GEAR 一线研究员押的赌。如果他赌对了,物理 AGI 这条线就第一次形成了类似 LLM "下一词预测自监督" 那样的稳定训练信号;如果赌错了,2027 年再回来看这一期。但他不是评论员说"我看好这条路"——他是身在闭环建设当中的人,给了一个 deadline。
四、Anthropic 不做物理 AI 是不是 miss?
这一期里特别反共识的一段判断在这里。曼祺问得很直白:「你觉得 Anthropic 不做这个方向会是一个 miss 吗?还是无所谓?」
高深远回得也直白:
"首先不会 miss 吧,就是我感觉你能统治整个——比如说虚拟世界的这种 agent 已经是很强了。"
然后他把整个物理 AGI 的赛道拆成两条路:
"一种就是你现在就开始去碰机器人、碰 robot data,然后相当于是我做 robot 的世界模型,我做 robot 的 policy。对,然后这可能是现在大多数浮出来的 startup——包括比如说像我们——大家都在做的。"
"然后另一种路线就是说……我首先得有个很强的这种 agent,它看各种图,然后就是它解决各种虚拟的 task……他们的路线可能就是相当于是我先搞一个很强的基模,他们其实也可以叫自己一个世界模型,因为它有很多 world knowledge。"
这段判断的含金量在哪里?它说的是:物理 AGI 不是只有一条路通——你既可以"从机器人侧打",也可以"从虚拟基模侧打"。Anthropic 选了后者。它把全部资源砸在做一个能解决任何虚拟 task 的强 agent 上,文本作为 action 输入也能驱动一个隐含的"世界模型"——只不过这个世界模型从来没被叫过这个名字。
这里有一个推论高深远没说,但我们可以替他说出来。这两条路的合并点在哪里?——在"基模足够强到可以直接被用作具身策略"那一刻。GPT 也好、Claude 也好,最终都会被人当作 robot 的 high-level planner 用——你只需要在它后面接一个低层 controller。从这个角度看,Anthropic 是赌虚拟 agent 的胜出会反向吃掉物理具身;GEAR 是赌物理具身的循环跑通会反向喂强基模。两边在赌方向相反的同一个事实。
如果你是一个商业读者,这一段读三遍——它是当前所有 AI 公司估值逻辑底下,特别关键的一个分叉点。
五、创业窗口:在大公司垄断的赛道里,小团队的位置在哪里
听完前四节读者很容易得出一个结论——这条路是大公司的游戏,看视频要算力、训世界模型要 GPU、自进化循环还要至少一个不弱的视频基模做底。普通创业公司没机会。
高深远的判断不是这样:
"首先我感觉也没有那么让人绝望。首先现在数据的供应商很多,然后价格也都会通过竞争打下来。所以可以想象未来大家所有人都会有很多 data。然后另外就是 GPU 和模型的效率也都会持续发展。所以最终这个也会变成一个大家都能做的事情。"
"然后包括这个 loop 里,其实有很多个 component……怎么去设计一个很好的提供 reward 的 agent,或者说怎么去设计一个比较泛化的 policy 和世界模型。这个你都可以在一个合理的实验 setup 下去验证,你可以有自己的专长的垂直面。就比如说家居或者说其他什么的,然后在这个里面把这个 loop 构建起来。"
这段话给创业公司画出了两个具体口子:
第一个口子是"垂直 loop"。家居、医疗、工业流水线、农业——任何一个明确的物理场景,都可以独立做一套世界模型 + 策略 + agent 的小循环。决定胜负的是 loop 能不能在你这个垂直场景里跑通,不是模型的绝对规模。这跟 LLM 时代垂直 SaaS 的逻辑结构是一致的——通用基模归大公司,但每个垂直应用都有自己的微调护城河。
第二个口子是 loop 里的某一个组件。Reward agent 怎么设计、Policy 怎么训出泛化能力、世界模型怎么避免级联误差——这每一个子问题都能单独支撑一家公司。GEAR 自己内部也只是把 DreamDojo 和 DreamZero 推到了 prototype,没人有精力把整个 loop 的每个角落都做精——这就是创业公司的位置。
关键约束:高深远在节目最后给了一个非常清醒的提醒——「假如说不能直接去 access 到一些最强的预训练模型的话」,创业公司「会有一个延迟」。在这个意义上,不掌握视频基模的创业公司,必须押对一件事——开源生态会跟得上。英伟达的 Cosmos 走开源路线、字节的 WAM 部分开源——只要这条开源链不断,垂直创业就成立;一旦闭源一拉开,创业公司从基模到 loop 的传导就会被卡死。
六、笔者个人观察
这一期有两个观察,商业读者或许比研究员更早用得上:
第一个观察是国内具身赛道的资金已经在往这条线上集结。从 2025 年 Q4 开始,国内具身智能融资节奏据我观察是肉眼可见地加快——头部几家具身公司每一轮的融资额度都在放大。这些公司大部分还停留在"做 VLA 策略 + 拼数据"那一层,但走到上游做 world model + policy + agent 三体闭环的,已经有少数几家在公开材料里隐约表态。这个融资节奏未必证明技术成熟——但说明资本已经按"循环将通"的预期下注。一线研究员说"循环要起来"的时候,二级一级资金不会等到事实跑通后才进。
第二个观察是英伟达 Cosmos 的开源对中国具身创业的实际意义。从我接触到的多个创业团队反馈来看,他们做 robot 策略的训练,往往要 fine-tune Cosmos 或者基于 Cosmos 起一个 fork。原因很简单:没有 Cosmos,他们就要先花 6 个月烧 GPU 自己训一个底层视频基模——这是大部分具身创业公司不能承受的成本。换句话说,英伟达通过 Cosmos 开源,事实上成了所有 robot 创业公司的公共底座。这跟当年 NVIDIA CUDA 在 GPU 计算栈上的位置同构——你以为黄仁勋只是卖卡,他在卡之上又埋了一层不可绕开的基础设施。
这两个观察连起来看是一句话——这条脊柱不只在英伟达 GEAR 内部跑,它正在被英伟达通过 Cosmos 开源外化为整个具身行业的公共底盘。这是一个比节目里讨论的"循环跑通"更长尾、更值得关注的产业事实。
七、声入商业说
声入商业不搬运播客内容,我们帮你判断这一期 109 分钟里值得带走的事。
这一期是 2026 年 5 月你能听到的、关于"AI 通向 AGI 的非 LLM 路径"很完整的一次一手描述。说话的人在 GEAR 内部,不是评论员。三件事值得带走:
- AGI 不是只有一条路。LLM scaling 是其中一条,世界模型 + 策略 + agent 三体闭环是另一条独立的脊柱。Anthropic 押前者、GEAR 押后者,两者都成立、都在赌方向相反的同一个事实。
- 2026 是这条脊柱第一次"跑通"的时间窗口。如果年底前你看到 GEAR 或 DeepMind 公布"循环初步收敛"的成果,这就是一个划时代的节点;如果年底没看到,再等一年。
- 创业公司在这条线上不是没有位置。垂直场景的小循环、loop 里的具体组件——两条路都开着。但它们的命脉是开源基模生态——Cosmos 和 WAM 这条线如果断,创业的传导也跟着断。
评论区话题:你身边有没有创业团队、研究员或投资人,已经在往"世界模型 + 策略闭环"这个方向押注?说说他们押的是垂直场景还是底层架构、判断今年跑通还是更晚——我们想知道实际节奏。
听原节目:小宇宙搜索"晚点聊 165",或点击文末「阅读原文」直达。
留言